Week1
In RL Monte Carlo methods allow us to estimate values (Not to get best policy) directly from experience, from sequences of states, actions and rewards. Learning from experience is striking because the agent can accurately estimate a value function without prior knowledge of the environments dynamics
- To evaluate state value, we need to know transition probabilities before DP. e.g. BlackJack: suppose the player’s sum is 14 and he chooses to stick. What is his probability of terminating with a reward of +1 as a function of the dealer’s showing card? All of the probabilities must be computed before DP can be applied, and such computations are often complex and error-prone.
Monte Carlo methods estimate values by averaging over a large number of random samples.
Use Monte-Carlo Prediction to estimate the value function for a given policy.

Undiscounted MDP where each game of blackjack corresponds to an episode. [example is interesting.]
Implications of Monte Carlo learning.
- We do not need to keep a large model of the environment
- We are estimating the value of an individual state independently of the values of other states.
- The computation needed to update the value of each state does not depend on the size of the MDP. Instead, it depends on the length of the episodes.
Monte Carlo VS DP:
- Ability to learn from actual experience
- From simulated experience
- Note that the computational expense of estimating the value of a single state is independent of the number of states. This can make Monte Carlo methods particularly attractive when one requires the value of only one or a subset of states
Off-policy learning VS On-policy learning?
Using Monte Carlo for Action-Values
Action-values are useful for learning a policy.
Exploring Starts: Random.
How to use Monte Carlo methods to implement a Generalized Policy Iteration (GPI) algorithm.

Exploring Starts is not a practical in every case. So we introduce \(\epsilon\)-soft policy
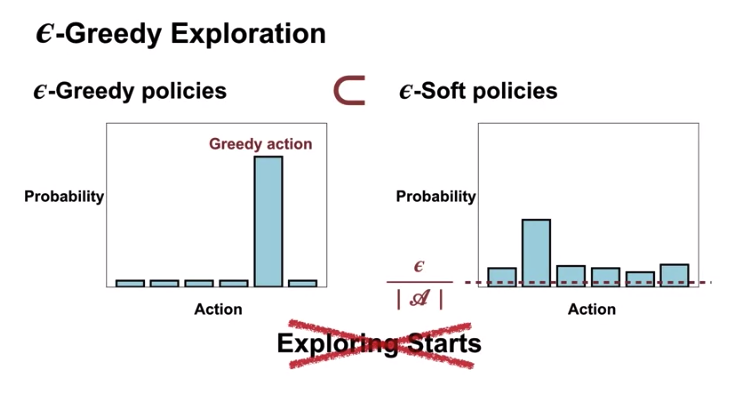
\(\epsilon\)-Greedy policies \(\subset\) \(\epsilon\)-soft policies

Why does off-policy learning for prediction:
- On-Policy: Improve and evaluate the policy being used to select actions.
- Off-Policy: Improve and evaluate a different policy from the one used to select actions
Target Policy: It is the policy that an agent is trying to learn i.e agent is learning value function for this policy.
Behavior Policy(Control Policy): 1. It is the policy that is being used by an agent for action select i.e agent follows this policy to interact with the environment.
Importantce Sampling:
- Use importance sampling to estimate the expected value of a distribution using samples from a different distribution



Off-policy-MC-prediction

Week2 Temporal Difference Learning
temporal difference learning definition:
\(V(S_t)\) <- \(V(S_t) + \alpha[R_{t+1} + \gamma V(S_{t+1})-V(S_t)]\)
Specialize in multi-step prediction learning
_learning.png)


Advantages of temporal difference learning:
- Do not require a model of the environment.
- Online and incremental
- Coverge faster than MC Methods
Week3 Sarsa: GPI with TD
This week introduces 3 types of estimating algo: Salsa, Expected Salsa and Q-learning. Expected Salsa and Q-learning are offline learning algo without importance sampling but Salsa is an online algo.
Why could offline learning go without importance? The agent is estimating action value with unknown policy, it doesn’t need importance sampling to correct for the diff in action selection.
The action-value function represents the returns following each action in a given state. The agents target policy represents the probability of taking each action in a given state.




Q-learning is learning the best action it could take [target policy] (without any randomness?) instead of the action it actually takes [behavior policy] –> it is a off-policy learning.

Learning on-policy or off-policty may perform differently in control
Expected Sarsa algorithm explicitly computes the expectation under its policy, which is more expensive than sampling but has lower variance.


Expected Sarsa with a target policy that’s greedy with respect to its action-values is exactly Q-learning:

Week 4
What’s models: Models are used to store knowledge about the dynamics. In this course, models store knowledge about the transition and reward dynamics.
- Sample Model:e.g. Sampling one instance to get reward
- Pros: Sample models require less memory
- Distribution model
- Pros: Distribution models can be used to compute the exact expected outcome/they can be used to access risk.
Planning with model experience: How one can leverage a model to better inform decision-making without having to interact with the world.
- Explain how planning is used to improve policies.
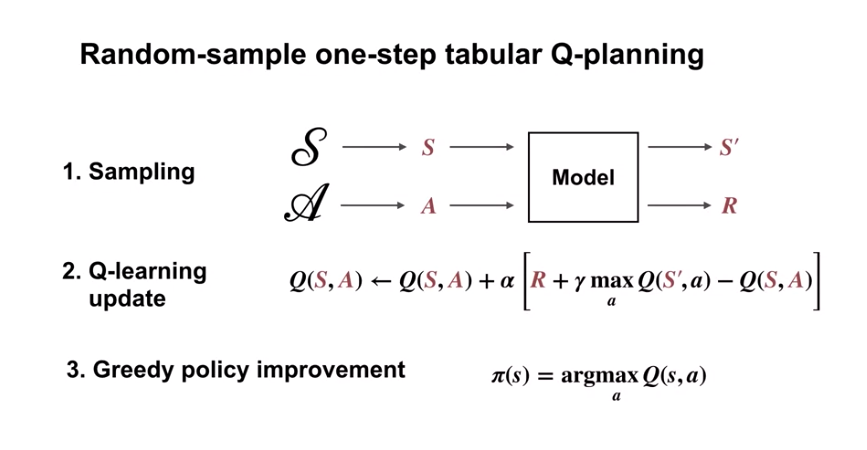
- Describe random-sample one-step tabular Q-planning.
The Dyna Architecture
- The Dyna architecture uses direct RL and planning updates to learn from both environment and model experience
- Direct RL updates use environment experience (sampling) to improve a policy or value function
- Planning updates use model experience (after getting rewards experience) to improve a policy or value function
Tabular Dyna-Q

How models can be inaccurate:
- Incomplete model
- Dyna-Q can plan with an imcomplete model by only samling state-action pairs that have been previously visited.
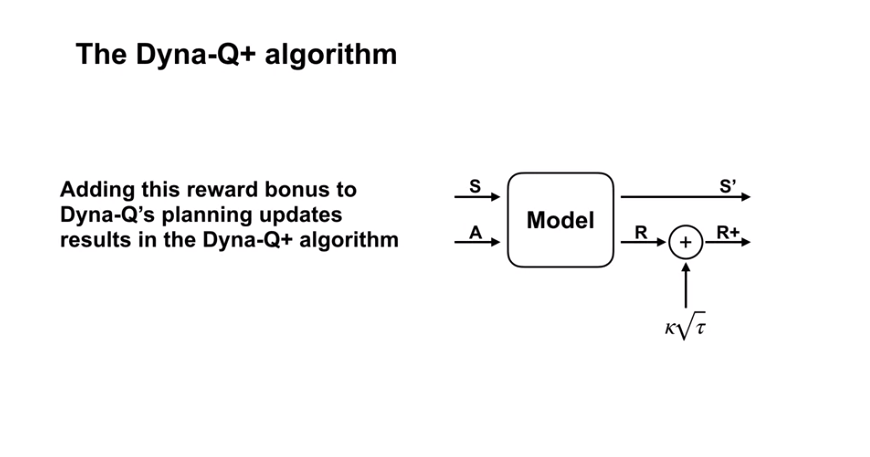
- Changing environment. * Dyna-Q+ uses exploration bonuses to explore the environment.